10.1. floor1_inverse_dB_table
The vector [floor1_inverse_dB_table] is a 256 element
static lookup table consiting of the following values (read left to right then
top to bottom):
1.0649863e-07, 1.1341951e-07, 1.2079015e-07, 1.2863978e-07,
1.3699951e-07, 1.4590251e-07, 1.5538408e-07, 1.6548181e-07,
1.7623575e-07, 1.8768855e-07, 1.9988561e-07, 2.1287530e-07,
2.2670913e-07, 2.4144197e-07, 2.5713223e-07, 2.7384213e-07,
2.9163793e-07, 3.1059021e-07, 3.3077411e-07, 3.5226968e-07,
3.7516214e-07, 3.9954229e-07, 4.2550680e-07, 4.5315863e-07,
4.8260743e-07, 5.1396998e-07, 5.4737065e-07, 5.8294187e-07,
6.2082472e-07, 6.6116941e-07, 7.0413592e-07, 7.4989464e-07,
7.9862701e-07, 8.5052630e-07, 9.0579828e-07, 9.6466216e-07,
1.0273513e-06, 1.0941144e-06, 1.1652161e-06, 1.2409384e-06,
1.3215816e-06, 1.4074654e-06, 1.4989305e-06, 1.5963394e-06,
1.7000785e-06, 1.8105592e-06, 1.9282195e-06, 2.0535261e-06,
2.1869758e-06, 2.3290978e-06, 2.4804557e-06, 2.6416497e-06,
2.8133190e-06, 2.9961443e-06, 3.1908506e-06, 3.3982101e-06,
3.6190449e-06, 3.8542308e-06, 4.1047004e-06, 4.3714470e-06,
4.6555282e-06, 4.9580707e-06, 5.2802740e-06, 5.6234160e-06,
5.9888572e-06, 6.3780469e-06, 6.7925283e-06, 7.2339451e-06,
7.7040476e-06, 8.2047000e-06, 8.7378876e-06, 9.3057248e-06,
9.9104632e-06, 1.0554501e-05, 1.1240392e-05, 1.1970856e-05,
1.2748789e-05, 1.3577278e-05, 1.4459606e-05, 1.5399272e-05,
1.6400004e-05, 1.7465768e-05, 1.8600792e-05, 1.9809576e-05,
2.1096914e-05, 2.2467911e-05, 2.3928002e-05, 2.5482978e-05,
2.7139006e-05, 2.8902651e-05, 3.0780908e-05, 3.2781225e-05,
3.4911534e-05, 3.7180282e-05, 3.9596466e-05, 4.2169667e-05,
4.4910090e-05, 4.7828601e-05, 5.0936773e-05, 5.4246931e-05,
5.7772202e-05, 6.1526565e-05, 6.5524908e-05, 6.9783085e-05,
7.4317983e-05, 7.9147585e-05, 8.4291040e-05, 8.9768747e-05,
9.5602426e-05, 0.00010181521, 0.00010843174, 0.00011547824,
0.00012298267, 0.00013097477, 0.00013948625, 0.00014855085,
0.00015820453, 0.00016848555, 0.00017943469, 0.00019109536,
0.00020351382, 0.00021673929, 0.00023082423, 0.00024582449,
0.00026179955, 0.00027881276, 0.00029693158, 0.00031622787,
0.00033677814, 0.00035866388, 0.00038197188, 0.00040679456,
0.00043323036, 0.00046138411, 0.00049136745, 0.00052329927,
0.00055730621, 0.00059352311, 0.00063209358, 0.00067317058,
0.00071691700, 0.00076350630, 0.00081312324, 0.00086596457,
0.00092223983, 0.00098217216, 0.0010459992, 0.0011139742,
0.0011863665, 0.0012634633, 0.0013455702, 0.0014330129,
0.0015261382, 0.0016253153, 0.0017309374, 0.0018434235,
0.0019632195, 0.0020908006, 0.0022266726, 0.0023713743,
0.0025254795, 0.0026895994, 0.0028643847, 0.0030505286,
0.0032487691, 0.0034598925, 0.0036847358, 0.0039241906,
0.0041792066, 0.0044507950, 0.0047400328, 0.0050480668,
0.0053761186, 0.0057254891, 0.0060975636, 0.0064938176,
0.0069158225, 0.0073652516, 0.0078438871, 0.0083536271,
0.0088964928, 0.009474637, 0.010090352, 0.010746080,
0.011444421, 0.012188144, 0.012980198, 0.013823725,
0.014722068, 0.015678791, 0.016697687, 0.017782797,
0.018938423, 0.020169149, 0.021479854, 0.022875735,
0.024362330, 0.025945531, 0.027631618, 0.029427276,
0.031339626, 0.033376252, 0.035545228, 0.037855157,
0.040315199, 0.042935108, 0.045725273, 0.048696758,
0.051861348, 0.055231591, 0.058820850, 0.062643361,
0.066714279, 0.071049749, 0.075666962, 0.080584227,
0.085821044, 0.091398179, 0.097337747, 0.10366330,
0.11039993, 0.11757434, 0.12521498, 0.13335215,
0.14201813, 0.15124727, 0.16107617, 0.17154380,
0.18269168, 0.19456402, 0.20720788, 0.22067342,
0.23501402, 0.25028656, 0.26655159, 0.28387361,
0.30232132, 0.32196786, 0.34289114, 0.36517414,
0.38890521, 0.41417847, 0.44109412, 0.46975890,
0.50028648, 0.53279791, 0.56742212, 0.60429640,
0.64356699, 0.68538959, 0.72993007, 0.77736504,
0.82788260, 0.88168307, 0.9389798, 1.
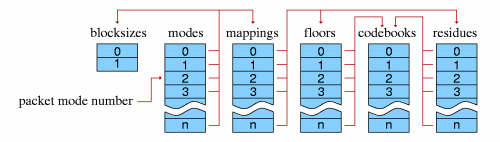
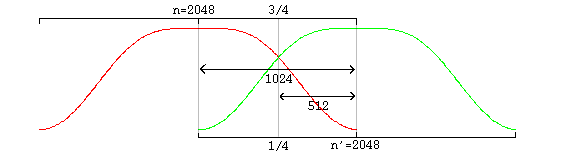
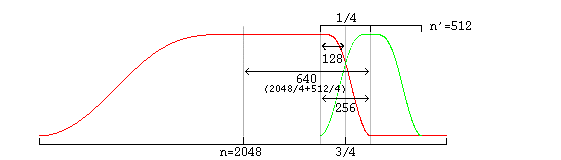
![[huffman tree illustration]](vorbis.files/hufftree.png)
![[underspecified huffman tree illustration]](vorbis.files/hufftree-under.png)
![[lsp map equation]](vorbis.files/lspmap.png)
![[equation for odd lsp]](vorbis.files/oddlsp.png)
![[equation for even lsp]](vorbis.files/evenlsp.png)
![[expression for floorval]](vorbis.files/floorval.png)
![[graph of example floor]](vorbis.files/floor1-1.png)
![[graph of example floor]](vorbis.files/floor1-2.png)
![[graph of example floor]](vorbis.files/floor1-3.png)
![[graph of example floor]](vorbis.files/floor1-4.png)
![[illustration of residue vector format]](vorbis.files/residue-pack.png)
![[illustration of residue type 2]](vorbis.files/residue2.png)
![[Xiph.org logo]](vorbis.files/white-xifish.png)